
Data modeling in Data Engineering
We talk about the core concept in data engineering, referring to the design of how data is structured and stored to support business processed.
A — What is the Data Modeling?
Data modeling is a core concept in data engineering, referring to the design of how data is structured and stored to support business processes. It represents the way data relates in the real world.
A good data model captures how communication and work naturally flow within your organization. A bad data model is haphazard, confusing, and incoherent. (from Fundamental of Data Engineering Book).
The data model covers some aspects: from conceptual, logical to physical, normalized data vs. denormalized data structures, dimensional modeling (with fact and dimension tables), and dive into techniques for handling data changes over time, including Slowly Changing Dimensions (SCD) and Change Data Capture (CDC).
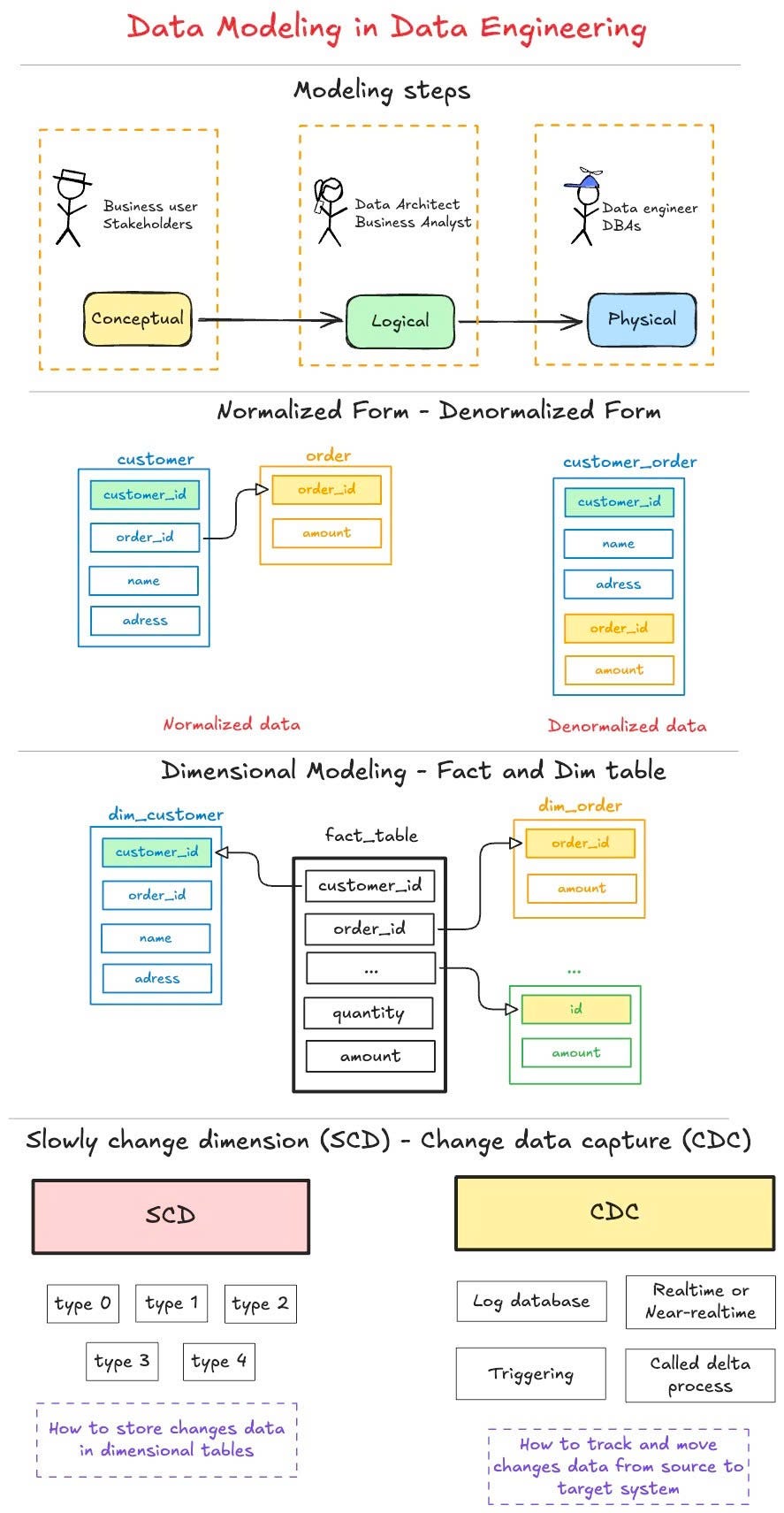
B — Conceptual — Logical — Physical
Conceptual: Contains business logic and rules and describes the system’s data, such as schemas, tables, and fields (names and types). When creating a conceptual model, it’s often helpful to visualize it in an entity-relationship (ER) diagram, which is a standard tool for visualizing the relationships among various entities in your data (orders, customers, products, etc.). These models are designed to communicate with stakeholders more efficient.
Logical: These model is about the details of conceptual model by adding some information such as field name, field type.
Physical: Defines how the logical model will be implemented in a database system. We would add specific databases, schemas, and tables to our logical model, including configuration details.
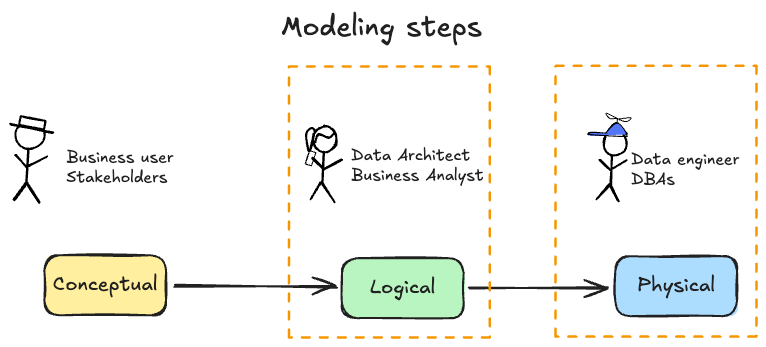
C— Normalized and Denormalized Data models
One of first considerations in data modeling in Data engineering & Big data is whether to organize data in a normalized or denormalized form.
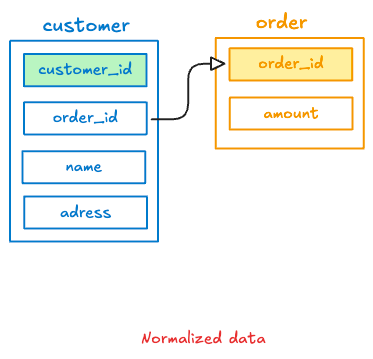
In normalized form, data is broken into many tables with relationships defined by primary keys and foreign keys. This reduces redundancy and inconsistency by ensuring each piece of data is stored only once. For example, in a normalized design, customer information might reside in one table and orders in another, linked by a customer ID. This structure optimizes data integrity (avoiding duplicate or conflicting records) and is typical for operational (OLTP) databases that handle transactions.
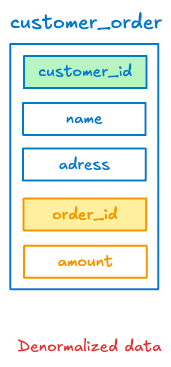
In denormalized form, data is consolidated into fewer tables (or even a single big table) to simplify queries and improve read performance because of large data in historical data. Denormalization intentionally duplicates certain data points, so that analytic queties and retrieve all needed information with fewer joins. In practice, many data warehouses use denormalized or partially denormalized schemas to speed up reporting and analytics. The trade-off is higher storage use and potential redundancy, but for read-heavy workloads, denormalization can significantly improve performance.
D— Dimensional Modeling: Facts and Dimensions
Dimensional modeling is a design technique especially popular in data warehousing. It structures data into fact and dimension tables, often organized as a star schema for intuitive querying. In a star schema, a central fact table contains quantitative metrics of interest, and it links to surrounding dimension tables that provide context for those metrics.
In a star schema, the fact table (center) stores numerical measures of a business process (e.g amounts, quantity, and foreign keys point to dimension table), and each dimension table (surrounding) holds descriptive attributes (such as product name of product table, customer name of customer table…) that provide context for those facts.
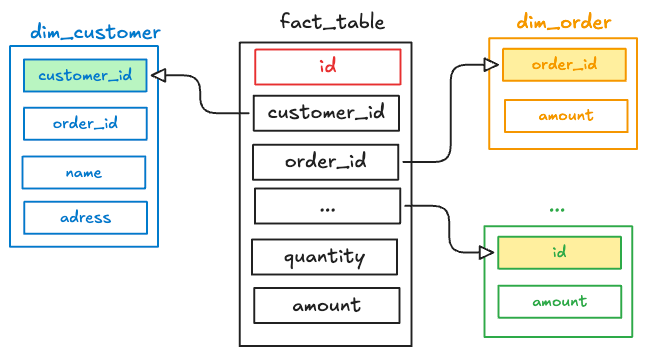
The key benefit of dimensional modeling is simpler queries and faster performance for analytics (read data, and do some join, agg operations). This approach was popularized for building analytic system like Warehouse and Lakehouse focused on user-friendly analytics.
E— Slowly changing Dimensions (SCD) and Change data capture (CDC)
Slowly change dimensions (SCD)
Slowly Changing Dimensions (SCD) are techniques for managing dimension data that changes over time. A slowly changing dimension is simply a dimension table where attribute values may change infrequently or unpredictably — for example, a customer’s address or a product’s description might be updated at some point. The challenge is deciding how to record these changes in the data model so that historical analysis remains accurate. SCD methods provide strategies to handle updates to dimension records without losing valuable history.
When a dimension attribute (say, a customer’s location or a product’s price) changes, we have a few options on how to reflect that change in the data warehouse. Kimball’s methodology defines several SCD “types” — commonly Types 0, 1, 2, 3, etc. — which range from doing nothing to preserving full history in separate records. The two most widely used types are SCD Type 1 and SCD Type 2:
Type 0: No change allowed.
Type 1: Overwrite existing dimension records. No history is kept; the dimension table always reflects the latest state. This is super simple and means you have no access to the deleted historical dimension records.
Type 2: The most common approach for preserving history. Instead of overwriting, the system (compute engine) adds a new row in the dimension table with the updated attribute values, while marking the old record as expired. This way, you keep both the prior version and the new version of the dimension. Typically, Type 2 dimensions have additional fields such as EffectiveStartDate, EffectiveEndDate (or an active flag) to indicate the period during which each version was valid. Each version gets its own surrogate key. This allows fact tables to continue pointing to the appropriate historical dimension record so reports can accurately reflect the value that was true at the time of the fact event.
Type 3: Adding a previous value column to the dimension table
Change data capture (CDC)
While SCD deals with How to store changes in dimensional data, Change data capture (CDC) deals with how to track and move changes from source to target systems.
CDC is a design pattern and set of techniques in data engineering for identifying and capturing changes made in a source and then delivering those changes to another system (target) in realtime or near-realtime. In essence, CDC is about the replicating data changes (insert, upsert) from one system to another system in continuous fashion, rather than via bulk transfers.
In practice, CDC is used to keep data stores in sync or to feed data pipelines incrementally. For example, a company might use CDC to continuously stream changes from an operational database (where transactions occur) into an analytics database, data warehouse or LakeHouse. By capturing only what changed (the delta changes) and not the entire dataset each time, CDC enables efficient, low-latency data updates comparing with batch process via T-1 data date. This is essential for modern pipelines that require fresh data for reporting, dashboards, or machine learning features without imposing heavy loads on the source systems.
By understanding concepts and techniques Data modeling in Data engineering ensure that you can develop, maintain and build data system more efficient, keep the right data is available to right people at the right time with right context : )) Happy reading.